Building a ChatGPT solution with custom data using Azure OpenAI

A few weeks ago, I wrote about my initial experience with provisioning and using the ChatGPT model with Azure OpenAI Services. Since then, a lot has happened. GPT-4 was announced. Microsoft 365 Copilot was unveiled. Each day, we’re getting more news on generative AI. It’s fine – take it with a pinch of salt – eventually, these will feel just as regular as using your mobile phone to download an app from the app store. That used to be a futuristic endeavour, now it’s a chore.
On ChatGPT and custom data
As I wrote in my previous post, ChatGPT is available via Azure OpenAI services. This post is specifically using that instead of the public https://chat.openai.com service. That’s fine, too, but it’s more of a SaaS service, and I’d like to use the PaaS service myself.
Once you have a working Azure OpenAI (OAI) instance, you can deploy the default models, such as the most powerful GPT-3 model, text-davinci-003. In a more limited preview, you can also deploy gpt-35-turbo which ChatGPT was using during the initial launch in early 2023. These are all based on massive sets of data, that you do not manage.
So how about using our custom data? It’s possible with datasets, but they will always be based on one of the default models. So you’re literally building on the shoulders of the giants.
The benefit of using custom data is evident: training the models to ingest our custom data, which would allow us to use ChatGPT and the other models for more specific purposes.
Datasets
Datasets sound sophisticated, but they are – quite literally – text files. *sad trombone sounds*
You can make dataset files of up to 200 MB, and that’s a lot of text. But not just any text – they must be specifically crafted as JSONL files. Hold on, I know JSON – but what is JSONL? It’s JSON Lines. Each record is a line. That’s it.
A sample JSONL file that I’ve created looks like this:
{"prompt": "How to optimize making filtered coffee at home with a Moccamaster", "completion": "Water the filter paper"}
{"prompt": "How to make best coffee on a Moccamaster", "completion": "Use cold and clean water"}
{"prompt": "How to make coffee taste good on Moccamaster", "completion": "Weigh the coffee brew, use 6 grams per cup"}The syntax varies a bit, but safe to say, keep it simple – a prompt and a completion. The completion is the desired outcome. How did I create this? Well, I used ChatGPT. I used the following prompt: Generate a JSONL file of a dataset for Azure OpenAI with 3 examples.
You can then upload the custom dataset to an OAI instance of course choice.
But there are limitations right now
If you’re considering deploying ChatGPT with GPT-4 with your custom datasets, that’s not an option. You can only enrich the following three models: ada, babbage and curie. As you see, ChatGPT-style text-davinci-003 is not supported right now. This limits the usability of the datasets, as the three supported models are much simpler than what you’ve come to associate with “ChatGPT is intelligent” experiences.
I did try the most advanced of these, curie with my custom dataset.
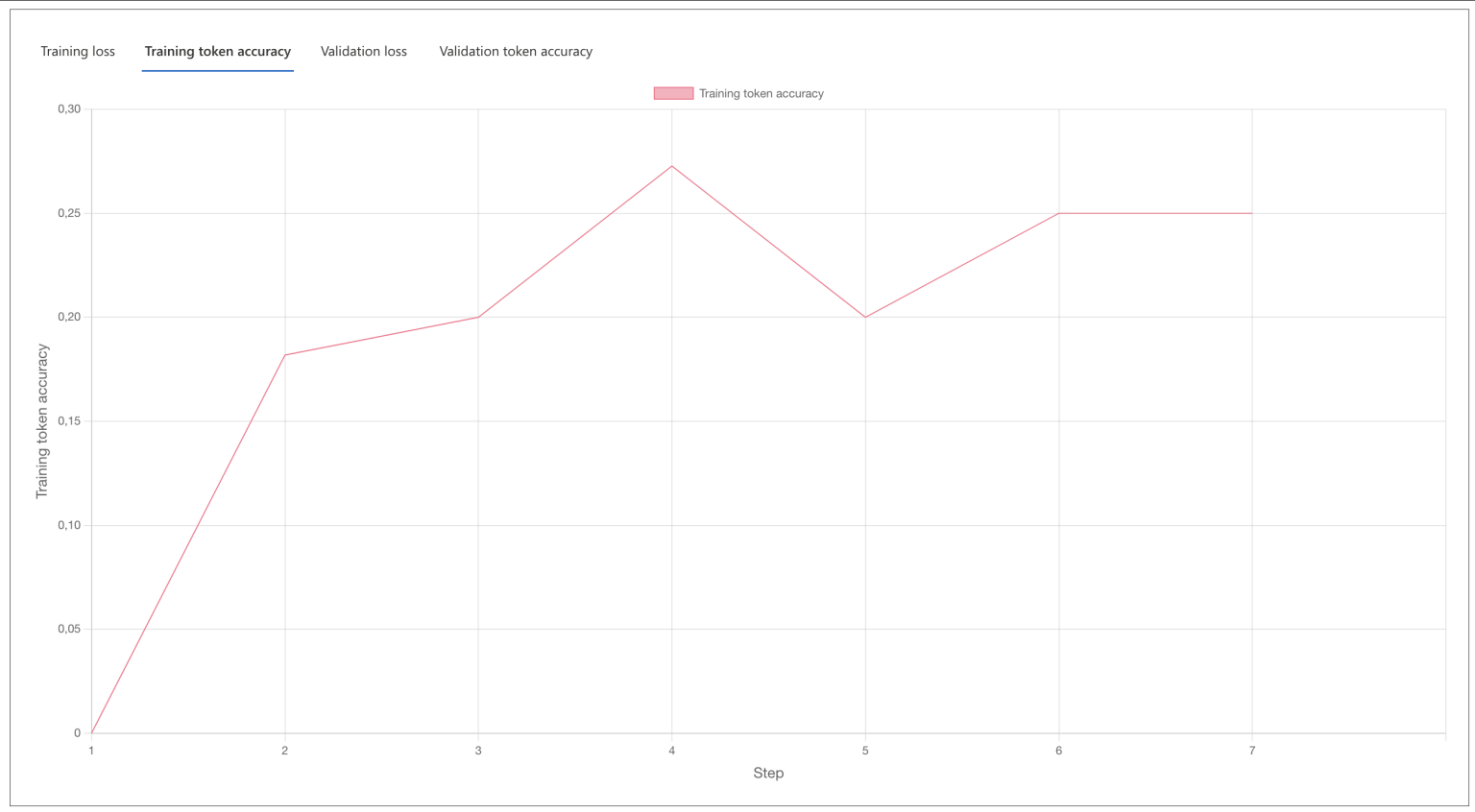
Training took 35 minutes. It reminds me of the Azure Automated ML experience from the past few years. You get plenty of data and results, but beyond that, it’s a black box. You cannot alter much, but you get a few advanced options – like the number of epochs. Admittedly my simplistic data is to blame, as I only had a few lines to initially test this experience.
Once the model is trained, you have to perform a customized deployment. This again took about 30 minutes to complete. Thankfully you should be able to re-use all of these if your dataset changes.
Testing the model, it’s not.. great.

This is most probably because the curie model is not ChatGPT per se. According to Microsoft guidance, the curie model is “..capable for many nuanced tasks like sentiment classification and summarization. Curie is also good at answering questions and performing Q&A and as a general service chatbot.”
I also did not provide any validation data, which I perhaps should have to make the results rank better. Beyond that, the process works and it’s fairly simple.
For larger files you’d obviously build an automated pipeline that pushes data directly as JSONL-files to Azure Storage, and they get picked up automatically from there. For small tests like mine, it’s not worth building that initially.
Closing thoughts
It’s a bummer you cannot enrich the davinci models, at least not right now. I like that the data can be ingested from simple text files. It’s still super early days, and everything I’ve tested here is very much in preview, and mostly limited.
I’m anxious to see how these services evolve. Yet, at the same time, I see that these are additional toosl to enrich your solutions – not something that would fully replace them.