Building my own RSS feed generator using .NET Core and the new System.Text.Json assembly

It’s that time again! And by this I mean I was thinking of grabbing a cup of coffee, splashing out a few lines of code and have something useful come out.
The way I seem to make learning easier for me is to build something. Many times when I’m in the middle of debugging some code, I realize the solution I’m about to build has probably been done a thousand times already, by more experienced people. But that’s more than fine, as I’m always learning.
The problem
I’ve written earlier how I transformed my WordPress-based blog to a static website (see Running a static site in Microsoft Azure using WordPress for content management). This solution is still in use today, and I simply love the flexibility of it. I had a look at the new, and cool static site generators such as Hugo but I couldn’t invest the time for yet another transformation just now. Perhaps later.
One of the problems my current solution has that the static generator in WordPress isn’t capable of producing an RSS feed. As such, I cannot offer a feed to any of my readers. No-one complained about this, so it might also be that I am the last person to need this – but it wouldn’t hurt to have a fancy rss.xml sitting somewhere.
So, how to best generate such as feed? Perhaps there’s a WordPress plugin I could use in my backend. But I’ve been wanting to do a little bit more coding lately, so I chose to build a tool by myself.
Building the tool
The idea is simple. I need to generate an XML file, that advertises my recent blog posts and some additional metadata about myself. “How hard can it be”, I thought – again. Okay, not that hard but a little bit tricky still.
I need to fetch data from my WordPress instance, and then construct an XML file from that. Initially, I thought I’d be able to just read through the static HTML files after each publishes, but that proved to be too hacky.

The way these posts are sitting on the filesystem is not optimal for quickly reading through them, as the files are in HTML format. I wanted to avoid parsing HTML, if at all possible.
WordPress, on the other hand, exposes a neat and simple REST API. It’s accessible through /wp-json/wp/v2. It produces JSON, by default.
To try out my hypothesis, I used PowerShell to call the API:
Invoke-RestMethod -Method GET -Uri "https://jussiroine.com/wp-json/wp/v2/posts?order=desc&per_page=1" | ConvertTo-JsonThis produces a nice JSON to play with:
{
"value": [
{
"id": 3258,
"date": "2019-08-20T10:45:46",
"date_gmt": "2019-08-20T07:45:46",
"guid": {
"rendered": "https://jussiroine.com/?p=3258"
},
"modified": "2019-08-20T10:45:47",
"modified_gmt": "2019-08-20T07:45:47",
"slug": "a-look-at-azure-costs-based-on-a-real-solution",
"status": "publish",
"type": "post",
"link": "https://jussiroine.com/2019/08/a-look-at-azure-costs-based-on-a-real-solution/",
"title": {
"rendered": "A look at Azure costs based on a real solution"
},
"content": {
"rendered": "\n\u003cp\u003eI\u0026#8217;ve used and worked with Microsoft Azure for a decade now. Often I\u0026#8217;m working in customer subscriptions, and don\u0026#8217;t have to worry about the cost \u003cem\u003ethat\u003c/em\u003e much. Obviously many times customers are <snip>",
"protected": false
},
"excerpt": {
"rendered": "\u003cp\u003eI\u0026#8217;ve used and worked with Microsoft Azure for a decade now. Often I\u0026#8217;m working in customer subscriptions, and don\u0026#8217;t have to worry about the cost that much. Obviously many times customers are querying about long-term cost, and what operating expenses they should plan and budget for. My own Azure subscriptions are financed by myself, and\u0026hellip;\u0026nbsp;\u003ca href=\"https://jussiroine.com/2019/08/a-look-at-azure-costs-based-on-a-real-solution/\" class=\"\" rel=\"bookmark\"\u003eRead More \u0026raquo;\u003cspan class=\"screen-reader-text\"\u003eA look at Azure costs based on a real solution\u003c/span\u003e\u003c/a\u003e\u003c/p\u003e\n",
"protected": false
},
"author": 2,
"featured_media": 3270,
"comment_status": "open",
"ping_status": "open",
"sticky": false,
"template": "",
"format": "standard",
"meta": {
"twitterCardType": "",
"cardImageID": 0,
"cardImage": "",
"cardTitle": "",
"cardDesc": "",
"cardImageAlt": "",
"cardPlayer": "",
"cardPlayerWidth": 0,
"cardPlayerHeight": 0,
"cardPlayerStream": "",
"cardPlayerCodec": ""
},
"categories": [
201,
334
],
"tags": [
244
],
"_links": {
"self": "",
"collection": "",
"about": "",
"author": "",
"replies": "",
"version-history": "",
"predecessor-version": "",
"wp:featuredmedia": "",
"wp:attachment": "",
"wp:term": " ",
"curies": ""
}
}
],
"Count": 1
}Having built something similar earlier to ping my car (Building a command-line utility using .NET Core and C# to track my car), I figured I’d just go that route.
I remember reading about the new System.Text.Json namespace, which includes a JsonDocument class as part of .NET Core 3.0 Previews. I’ve used RestSharp and Newtonsoft.Json before, so perhaps it was time to try out something new. I’m willing to take a calculated risk here.
As this is a tool purely for myself, I chose to create a .NET Core console app using C#.
First, a few variables:
var WP_URL = "https://jussiroine.com";
var API_URL = "/wp-json/wp/v2";
var QUERY = "/posts";
var PARAMS = "?order=desc&per_page=10";I’m anticipating my RSS feed to have 10 items at a time. Remember, that I’m targeting my internal WordPress instance to produce the XML file and publishing that in my public static website as an rss.xml -file.
Next, I’m calling the API and retrieving whatever it produces:
HttpClient client = new HttpClient();
var response = client.GetStringAsync(WP_URL + API_URL + QUERY + PARAMS).Result;I didn’t bother writing any error-checking logic. I’ll get to that, someday.
Time to start processing JSON! Sadly, the JsonDocument class is so new that I had a hard time finding good examples to learn more. First, I’m getting the document and parsing it. Then I’ll pick up the Root Object from the document, which is ‘value’:
var document = JsonDocument.Parse(response);
var root = document.RootElement;Next, I need to start crafting my RSS data structure. For .NET, there’s a nice class called SyndicationFeed that does the heavy lifting.
I need to set a few variables, and instantiate a new class for the SyndicationFeed first:
var feedTitle = "Jussi Roine";
var baseURL = "https://jussiroine.com";
var feed = new SyndicationFeed();
feed.Title = new TextSyndicationContent(feedTitle);
feed.Description = new TextSyndicationContent("I write about things that interest me – mostly about Microsoft, cloud technologies, productivity and being outside my comfort zone. I’m a Microsoft Regional Director and Most Valuable Professional, and I work with Microsoft technologies.");
feed.Copyright = new TextSyndicationContent("Copyright " + DateTime.Now.Year + " | Jussi Roine");
feed.LastUpdatedTime = new DateTimeOffset(DateTime.Now);
feed.Generator = "RSSGenerator";
feed.ImageUrl = new Uri(baseURL + "/content/uploads/2019/04/jro.png");
feed.Id = baseURL;
SyndicationLink link = new SyndicationLink(new Uri(baseURL + "/rss.xml"));
link.RelationshipType = "self";
link.MediaType = "text/html";
link.Title = "Jussi Roine Feed";
feed.Links.Add(link);
link = new SyndicationLink(new Uri(baseURL))
{
MediaType = "text/html",
Title = "Jussi Roine"
};
feed.Links.Add(link);Next, it’s time to loop through the JSON document and populate the feed items to my RSS feed object. It’s far from optimal, but it works (on my machine..), so I’m perhaps a little bit happy for this bit of code:
var items = new List<SyndicationItem>();
foreach (var prop in root.EnumerateArray())
{
var item = new SyndicationItem();
// title - remove {rendered..}
var rawTitle = JsonDocument.Parse(prop.GetProperty("title").ToString());
var postTitle = rawTitle.RootElement.GetProperty("rendered").ToString();
// strip HTML entities from title
postTitle = HttpUtility.HtmlDecode(postTitle.ToString());
postTitle = Regex.Replace(postTitle, "<.*?>", String.Empty);
postTitle = Regex.Replace(postTitle, @"^\s+$[\r\n]*", string.Empty, RegexOptions.Multiline);
// postLink
var postLink = baseURL + "/" + prop.GetProperty("link").ToString().Substring(30);
// content - remove {rendered..} and HTML tags
var rawPostContent = JsonDocument.Parse(prop.GetProperty("content").ToString());
var rootContentDoc = rawPostContent.RootElement.GetProperty("rendered");
// strip HTML from content
var postSummary = HttpUtility.HtmlDecode(rootContentDoc.ToString());
postSummary = Regex.Replace(postSummary, "<.*?>", String.Empty);
postSummary = Regex.Replace(postSummary, @"^\s+$[\r\n]*", string.Empty, RegexOptions.Multiline);
var postDate = prop.GetProperty("date").ToString();
item.Title = TextSyndicationContent.CreatePlaintextContent(postTitle);
item.Links.Add(SyndicationLink.CreateAlternateLink(new Uri(postLink)));
item.Summary = TextSyndicationContent.CreateHtmlContent(postSummary);
var date = DateTime.Parse(postDate);
item.PublishDate = new DateTimeOffset(date);
item.Authors.Add(new SyndicationPerson("[email protected]", "Jussi Roine", baseURL));
items.Add(item);
}There’s not much going on, but some things I needed to work on. First, I needed to decode all HTML entities, and them remove them. The RSS structure suggests that content should be plain-text, so I’m using a few regular expressions to rid myself of those pesky HTML entities. Stack Overflow is littered with opinions on this, so I just chose to do it my way.
Next, I struggled a bit in reading the post content, as it’s an array within the JSON document, and JsonDocument wasn’t especially helpful here. After requesting help on Twitter, I realized the solution – I simply instantiate another JsonDocument based on the array. Again, far from optimal – but it works, and I don’t have all morning to finish this tool.
Last, I need to dump all this to an acceptable XML format:
feed.Items = items;
var settings = new XmlWriterSettings
{
Encoding = Encoding.UTF8,
NewLineHandling = NewLineHandling.Entitize,
NewLineOnAttributes = true,
Indent = true
};
XmlWriter writer = XmlWriter.Create(@"C:\temp\rss.xml", settings);
feed.SaveAsRss20(writer);
writer.Flush();And this produces a valid RSS file for me. It’s crucial to set encoding to UTF-8, as otherwise, C# (and StringBuilder that I first used) defaults to UTF-16, which causes all sorts of headaches later on.
Verifying the results
Opening rss.xml with Notepad++, I can verify that it looks to be mostly correct:
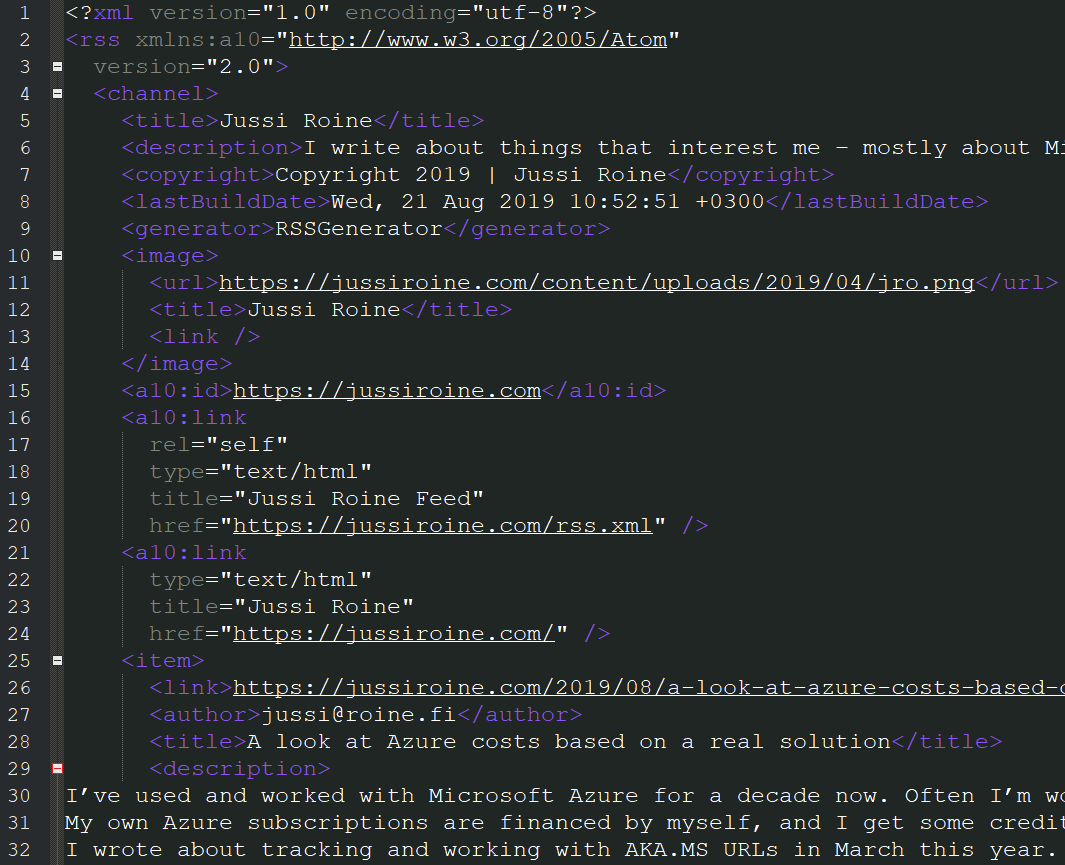
I uploaded the file to my blog, and pointed Feedly to it:
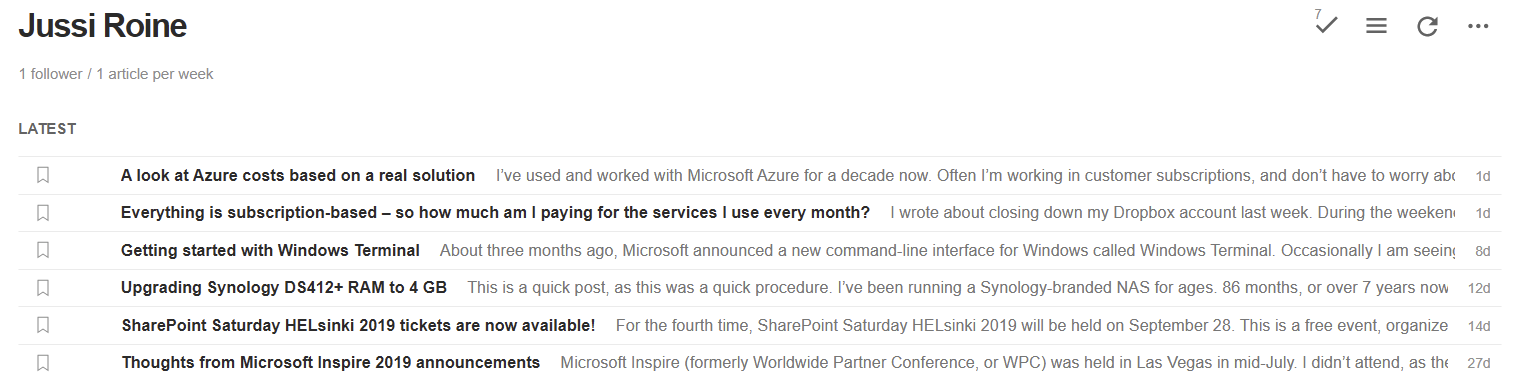
All that is left is a nice RSS icon and a link to the file on my blog!
I realize there’s quite a bit of tweaking to be done, especially with formatting and additional metadata the RSS feed could expose. That’s perhaps an exercise for another morning coffee!
You can view the RSS feed here.