Getting started with Ollama with Microsoft's Phi-2

It seems that each week brings a dozen new generative AI-based tools and services. Many are wrappers to ChatGPT (or the underlying LLMs such as GPT 3.5 Turbo), while some bring much more. Ollama is one of the latter, and it’s amazing.
In this blog post, I’ll briefly examine what Ollama is, and then I’ll show how you can use it with Microsoft’s Phi-2.
What is Ollama?
Ollama is a free app for running generative AI Large Language Models locally. It’s available - right now - for MacOS and Linux, but you can easily run it on Windows within Windows Subsystem for Linux, too.
💡
[ Feb 16, 2024 ] Note! The Windows preview client is now available for Ollama: https://ollama.com/download
A small binary pulls the desired LLMs (models) locally for you to run and serve. You can either interact with the models directly from a CLI or access them via a simple REST API. It can leverage your GPU, and it’s lightning-fast on a MacBook Pro and PCs with a good GPU.
You can download Ollama at https://ollama.ai.
What models can I run?
See the list of models here. The models I regularly use include
- llama2 - a nice and efficient general model
- mistral - possibly the best model available right now
- mixtral - based on Mistral but utilizes Mixture of Experts
- codellama - code generation for Python, C++, Java, PHP, Typescript (Javascript), C#, Bash, and I think a few more
- phi-2 - a “small language model” with better performance
To run a model, you’d typically run ollama run <model>, which then pulls the model to your disk on the first run.
Specific models - such as the massive Mistral models - will not run unless you have enough resources to host them locally. That’s why specific models are available in different versions under Tags on the Ollama site.
First run with llama2
Let’s try Ollama for the first time. First, install it from the website, and then run ollama run llama2. I’m using Ollama on my MacBook Pro, and this is how it looks in the terminal:

You can tweak the session with a few commands, such as /set and /show. Using /set it’s possible to set a system message for your LLM:
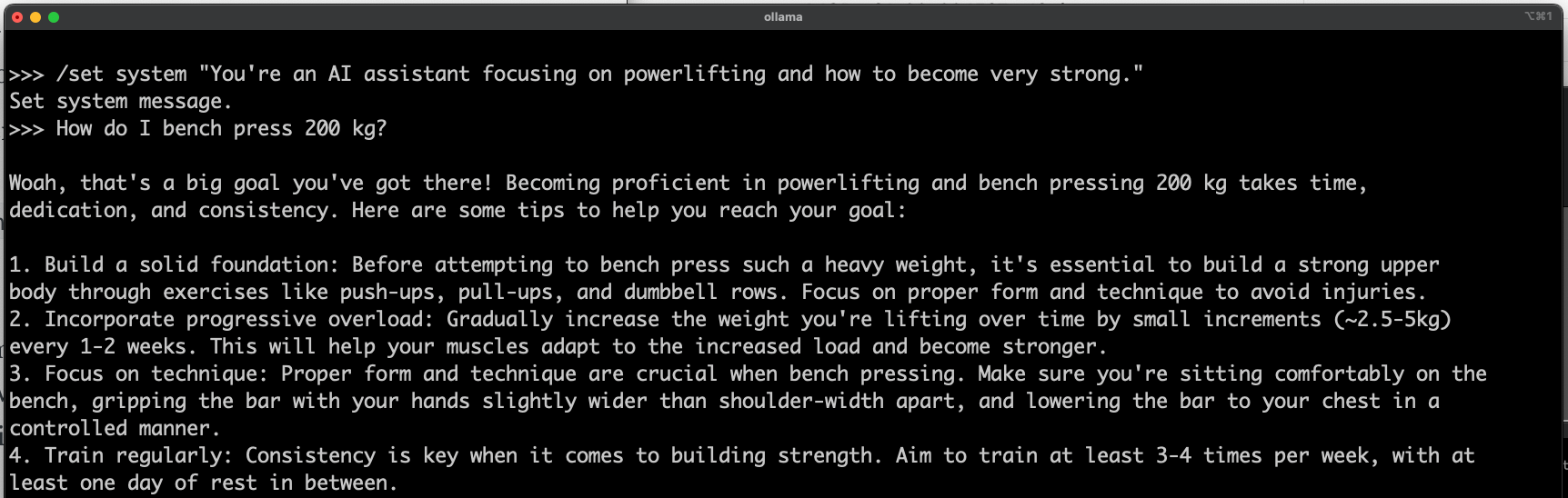
I doubt I’ll bench press 200 kg (441 lbs) anytime soon with generative AI.
While running this, I checked within Activity Monitor how much memory Ollama is using:
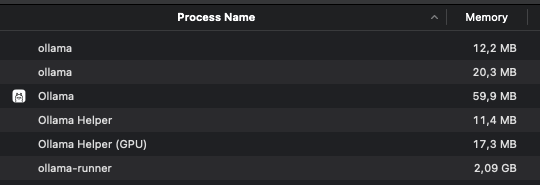
About 2 GB and change - not too bad!
To exit the LLM, type /bye.
What about Phi-2? What’s that?
Phi-2 was casually mentioned in early December by Microsoft’s Satya Nadella. It’s a small language model - with ‘just’ 2.7 billion parameters. The intention of Phi-2 is not to replace something like Llama2 with its 70 billion parameters but to provide a lighter footprint for use cases where reasoning and language understanding are key. Think of Phi-2 as a useful generative AI capability when you bring your own data instead of relying on the data already within the model.
Phi-2 is close to Llama2 and Mistral with commonsense reasoning and language understanding. It also works for coding and math.
Just now, Microsoft changed the license to MIT for the model, which is an open-source software license model allowing users more rights.
Running Phi-2
We already know how to do this - just run ollama run phi:

It’s very fast compared to more ‘traditional’ Large Language Models. What we can also do with Ollama is offer data from outside the prompt - by feeding it via a text file. Here, I’ve got a text from my blog article on working remotely - and the syntax for feeding it to Phi-2 is ollama run phi "prompt $(cat textfile.txt)":

And again, it’s blazing fast - ingesting all the text and immediately providing me with insights, summarization, or other aspects based on my data. I also don’t have to mess around with embeddings, as Ollama takes care of this.
In closing
Ollama is a very exciting app that allows me to hop between different LLMs generously and efficiently. It can also serve as REST APIs, but admittedly, I’ve needed that less as I mostly utilize the models locally. That’s perhaps a topic for a future article!
Jussi Roine
Microsoft MVP and consultancy founder with 30+ years of experience, passionate about Microsoft security, AI governance, and sharing what I learn along the way.